
Software Engineer at Cesbit.
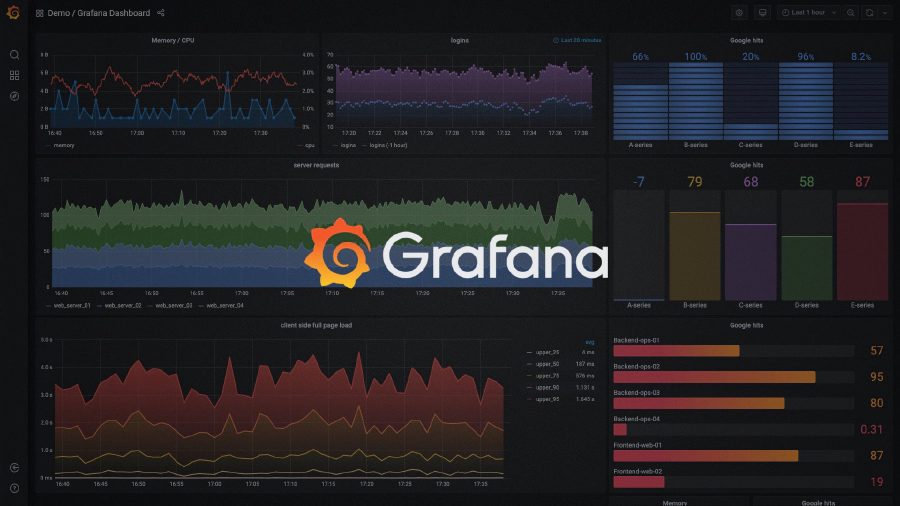

Update: example Grafana using SiriDB HTTP API
This second blog on setting up a Grafana dashboard with SiriDB as a data source demonstrates how to use the new built-in SiriDB HTTP API.
Since version 2.0.36 of SiriDB and version 1.2.0 of the Grafana-SiriDB-HTTP-datasource, it is possible to use a build-in HTTP API for connecting with Grafana, instead of using the SiriDB-http and SiriDB-admin tools. The HTTP API can do the same things as both tools combined; it can be used to create and manage databases, and query and insert data from and to SiriDB. This new feature will be demonstrated in this blog and at the same time we create a attractive Grafana dashboard showing some data from the localhost and some information about the running SiriDB processes.
If you have read the first blog about “Using Grafana with SiriDB” then a couple steps may be somewhat repetitive. However be aware that there are some crucial parts different.
Prerequisites
We use a fresh Ubuntu 19.10 (desktop) installation so you might want to skip some steps or change some commands according to your operating system.
Update and install Git, Pip and libuv1 by using apt.
sudo apt update
sudo apt upgrade
sudo apt install libuv1 git python3-pip
We start by downloading the Python script (and this tutorial):
git clone https://github.com/SiriDB/grafana-siridb-http-example.git
cd ./grafana-siridb-http-example
Next we install SiriDB:
wget https://github.com/SiriDB/siridb-server/releases/download/2.0.36/siridb-server_2.0.36-0.tt1_amd64.deb
sudo dpkg -i siridb-server_2.0.36-0.tt1_amd64.deb
We don’t require SiriDB to start at startup so we disable the service:
sudo systemctl disable siridb-server.service
Let’s setup Grafana. First download and install Grafana:
sudo apt-get install -y adduser libfontconfig1
wget https://dl.grafana.com/oss/release/grafana_6.7.2_amd64.deb
sudo dpkg -i grafana_6.7.2_amd64.deb
And install the Grafana-SiriDB-Datasource plugin:
cd /var/lib/grafana/plugins/
sudo git clone https://github.com/SiriDB/grafana-siridb-http-datasource.git /var/lib/grafana/plugins/grafana-siridb-http-datasource
Configuration of SiriDB
SiriDB can scale data across multiple pools and each pool can have two servers for redundancy. We can play with this concept on a single host by running SiriDB multiple times using different ports. In a real scenario you should use different nodes but for now we will create four SiriDB nodes and setup two pools, each with two SiriDB servers.
This action will create four SiriDB configuration files and be aware that you enable the http_api_port by adding it to the configuration files (by default it is disabled):
for i in {0..3}; do `cat <<EOT > siridb$i.conf
[siridb]
listen_client_port = 900$i
server_name = %HOSTNAME:901$i
ip_support = ALL
optimize_interval = 900
heartbeat_interval = 30
default_db_path = ./dbpath$i
max_open_files = 512
http_api_port = 902$i
EOT` && mkdir dbpath$i; done
Start SiriDB
Now we can start the SiriDB servers! The following command starts the four SiriDB servers in the background.
for i in {0..3}; do siridb-server -c siridb$i.conf > siridb$i.log & done
Hint: you can view the output from a SiriDB process by using for example
cat siridb0.logortail -f siridb0.log.
Creating and managing a database using the HTTP API
Now we use the SiriDB HTTP API to create the actual database. SiriDB has a default service account sa with password siri which we will use.
For our tutorial we will only need a database with second precision. We also select a shard duration of 6 hours for this database because our measurement interval will only be a few seconds. Sometimes you might want to store one value per measurement in each hour or even per day in which case your database will perform better by using a larger shard duration.
Create the database on the first SiriDB server which is running on port 9000 using curl with basic authentication:
curl --location --request POST 'http://localhost:9020/new-database' \
--header 'Content-Type: application/json' \
--header 'Authorization: Basic c2E6c2lyaQ==' \
--header 'Content-Type: text/plain' \
--data-raw '{
"dbname": "tutorialdb",
"time_precision": "s",
"buffer_size": 8192,
"duration_num": "6h",
"duration_log": "3d"
}'
Now we have a database and we can use the default database user iris with password siri to extend the database
with a replica on the second server (running on port 9001):
curl --location --request POST 'http://localhost:9021/new-replica' \
--header 'Content-Type: application/json' \
--header 'Authorization: Basic c2E6c2lyaQ==' \
--header 'Content-Type: text/plain' \
--data-raw '{
"dbname": "tutorialdb",
"username": "iris",
"password": "siri",
"host": "localhost",
"port": 9000,
"pool": 0
}'
Collected some data
Ok, now everything is ready to collect data (we configure the other two SiriDB servers later in this tutorial). We use a Python script that collects some cpu, disk and memory data from the localhost and some information about the running SiriDB processes. All this data will be stored in a SiriDB database and by using a Grafana Dashboard we are able to monitor the data. Before we start the Python script to collect data we must install its dependencies:
pip install siridb-connector psutil
Start the script. The script accepts arguments which can be viewed with python mon2siridb.py -h. If you are following this tutorial then the defaults should be fine.
python mon2siridb.py &> mon.log &
Start and setup Grafana
Start (or restart) Grafana:
sudo systemctl restart grafana-server.service
Open a browser and go to http://localhost:3000. You should see the following page:

Sign-in by using username admin and password admin.
Click on Add data source to create the SiriDB data source. The URL follows the syntax: https://siridb-server1:http-api-port/query/dbname. Fill in the form like in the picture below (use siri as password):
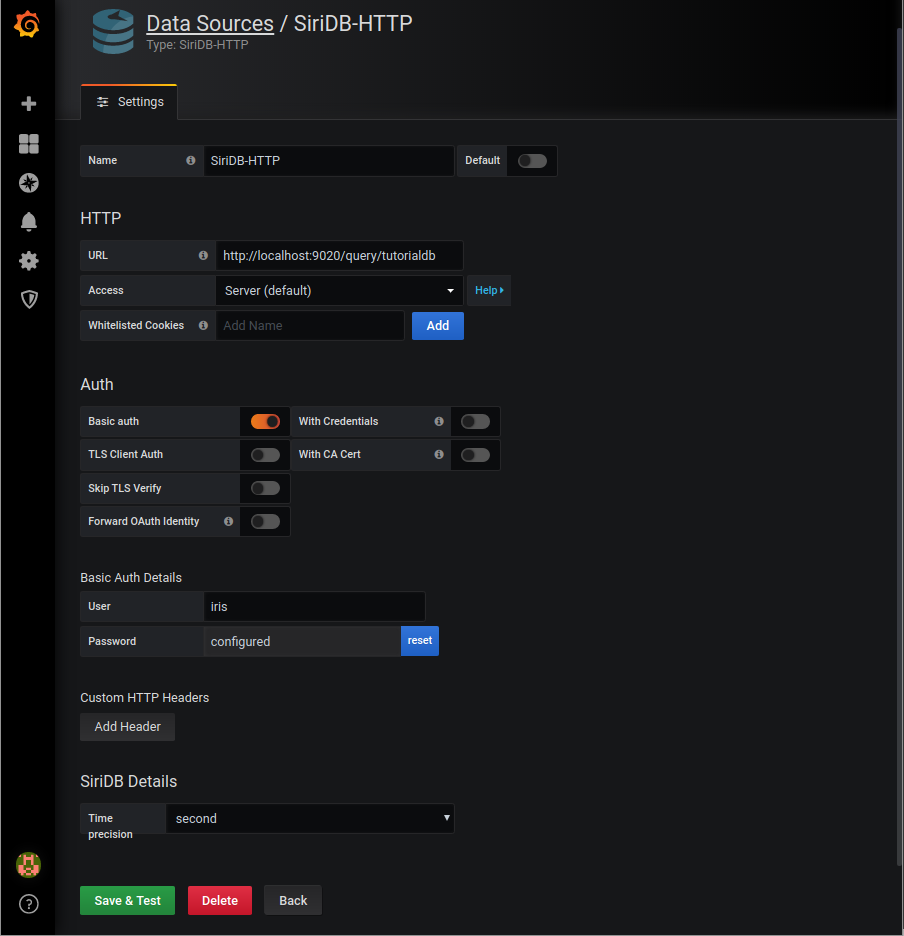
Click on Save and test this should return the message that everything is working!
Go to the menu and click on Dashboards -> Import
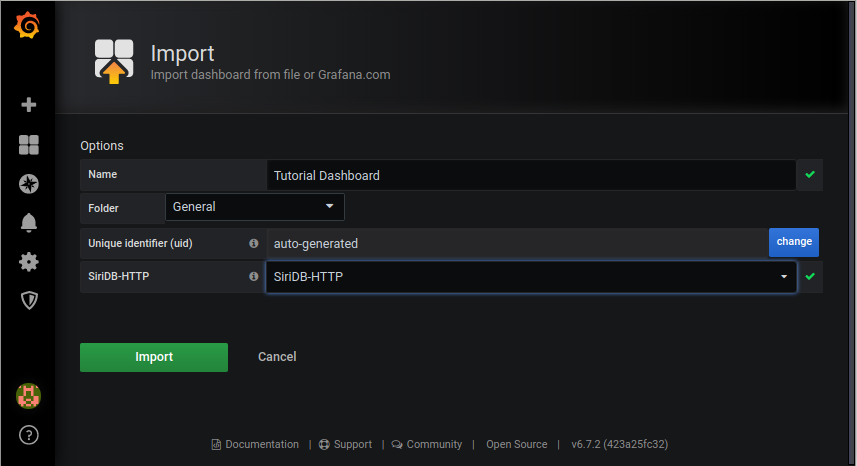
Click on Upload .json File and select the tutorial-dashboard.json from this folder.
In the next window you should choose the SiriDB HTTP data source.
After clicking on Import you should see a dashboard similar to this:
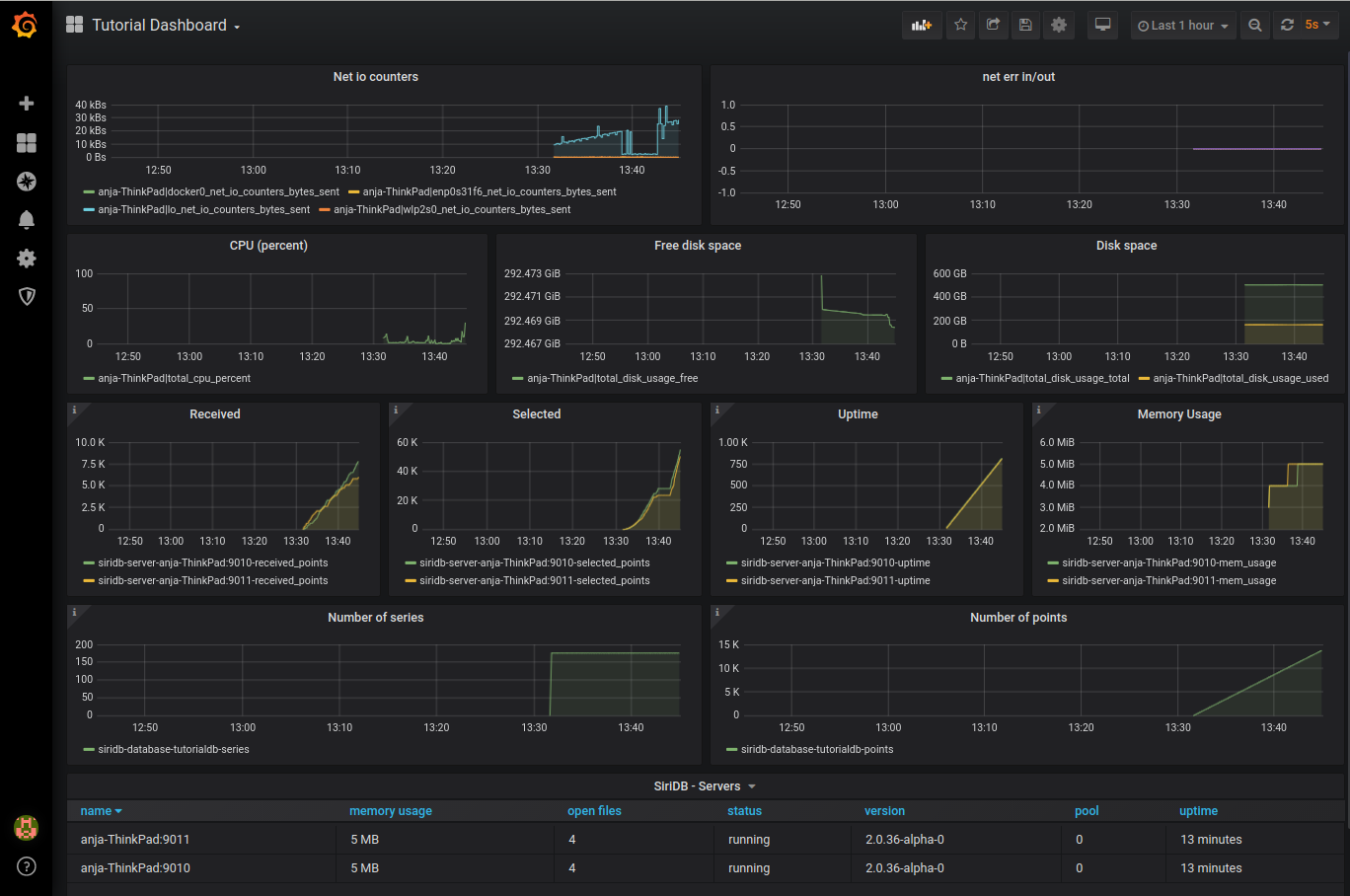
Working with Grafana and SiriDB using the HTTP API
We can now continue by expanding the database with another pool and use the third server on port 9002.
curl --location --request POST 'http://localhost:9022/new-pool' \
--header 'Content-Type: application/json' \
--header 'Authorization: Basic c2E6c2lyaQ==' \
--header 'Content-Type: text/plain' \
--data-raw '{
"dbname": "tutorialdb",
"username": "iris",
"password": "siri",
"host": "localhost",
"port": 9000
}'
In the dashboard you should see the new server. The status for the existing servers includes re-indexing while the series are spread across the pools.

Wait until the status for all three server is running and then create another replica on the fourth server (on port 9003):
curl --location --request POST 'http://localhost:9023/new-replica' \
--header 'Content-Type: application/json' \
--header 'Authorization: Basic c2E6c2lyaQ==' \
--header 'Content-Type: text/plain' \
--data-raw '{
"dbname": "tutorialdb",
"username": "iris",
"password": "siri",
"host": "localhost",
"port": 9000,
"pool": 1
}'
The dashboard should show the fourth server with status synchronizing

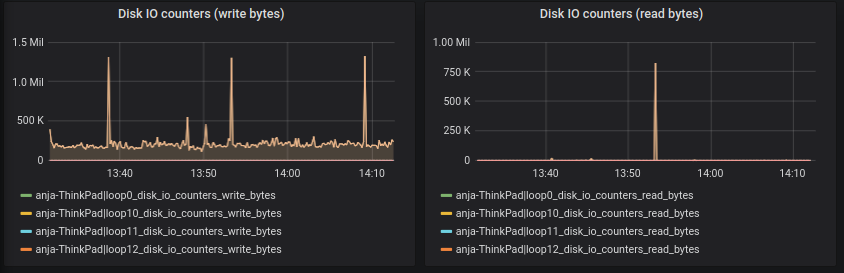
From this point on it should be rather easy to create your own Grafana Dashboard by using a SiriDB database. As an example we will add two extra graphs for Disk IO counters.
If you want to select series based on regular expression, then a best practice is to create a dynamic group. For the current example we create the following two groups:
disk_io_counters_read_bytes
curl --location --request POST 'http://localhost:9020/query/tutorialdb' \
--header 'Content-Type: application/json' \
--header 'Authorization: Basic aXJpczpzaXJp' \
--header 'Content-Type: text/plain' \
--data-raw '{
"q": "create group `disk_io_counters_read_bytes` for /.*disk_io_counters_read_bytes/"
}'
disk_io_counters_write_bytes
curl --location --request POST 'http://localhost:9020/query/tutorialdb' \
--header 'Content-Type: application/json' \
--header 'Authorization: Basic aXJpczpzaXJp' \
--header 'Content-Type: text/plain' \
--data-raw '{
"q": "create group `disk_io_counters_write_bytes` for /.*disk_io_counters_write_bytes/"
}'
Go back to Grafana and click on Add panel -> Add Query.
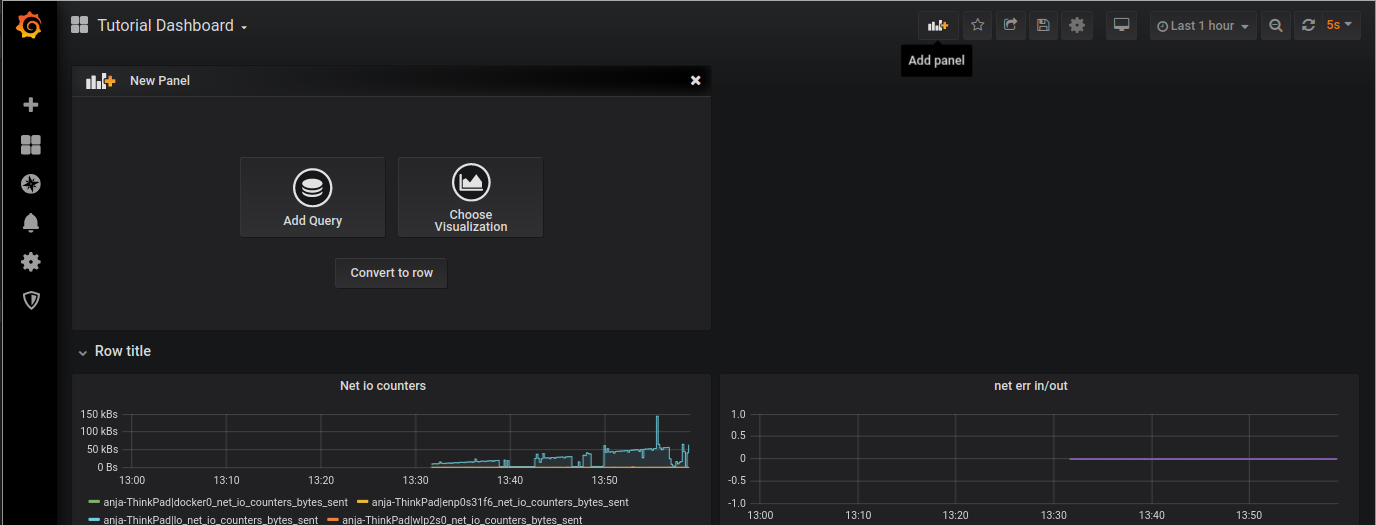
At select fill in `disk_io_counters_read_bytes`, choose max as aggregation and enable Diffps.
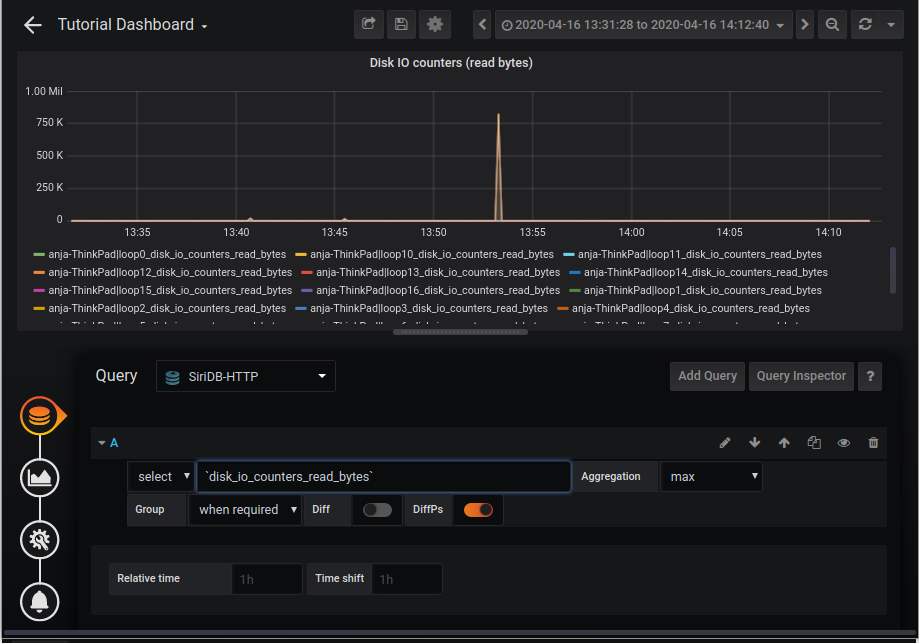
On the General tab you can change the panel title to “Disk IO counters (read bytes)”.
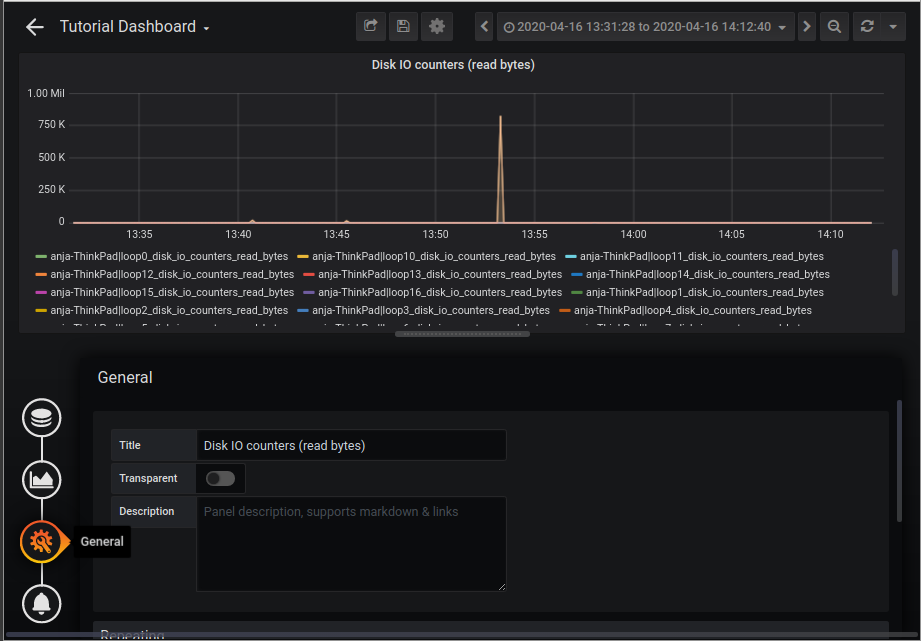
Repeat these steps for the write counters and when you are finished you should have the following result:
I hope this tutorial was helpful and I am looking forward to hear what you can create by using Grafana and SiriDB!